This workstream focuses on monetary policy and market reactions. Specifically, we are interested in whether policy information communicated in policy announcements drive market responses. We first focus on policy decisions, market forecasts and disagreements and find that markets react both expectedly and unexpectedly, pointing to an information signal. We then model language extensively which is used to correlate with market reactions. One limiting factor was subsetting the data, for which we trained a transformer neural network to improve outcomes.
Author Charl van Schoor
TBD
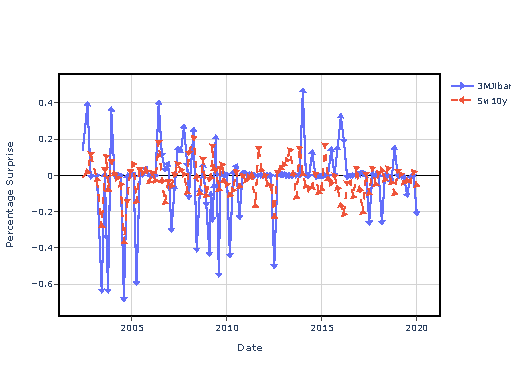
With this paper we analyse whether markets react to policy announcements. Using a combination of financial assets, we show that market react in expected and unexpected ways. As expected, when market forecasts are off markets react as expected by adapting to the new policy rate. However, When forecasts are correct, markets react by adjusting long term expectations even while controlling for forecast disagreement. This points to the presense of information signals present during communications.
Author Charl van Schoor
TBD
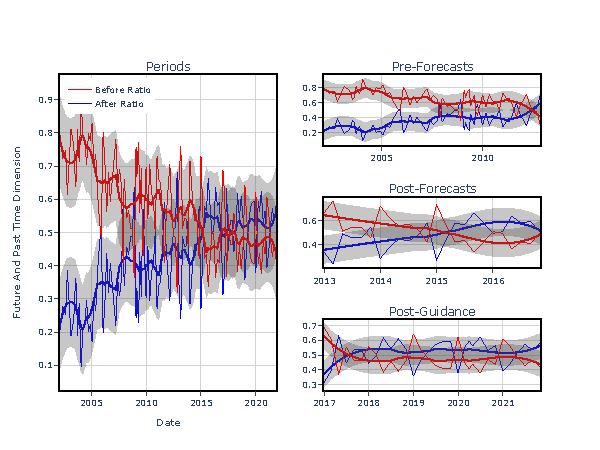
With this work we summarize changes in the SARB's MPC statements using various computational linguistics techniques. This includes modelling for sentiment, time, topics and communication consistency. Our analysis shows a dynamic evolution of policy communication with gradual changes over time. Moreover, we see a convergence in later years to a standardized template signaling an improvement in policy framework communication.
Author Charl van Schoor
TBD
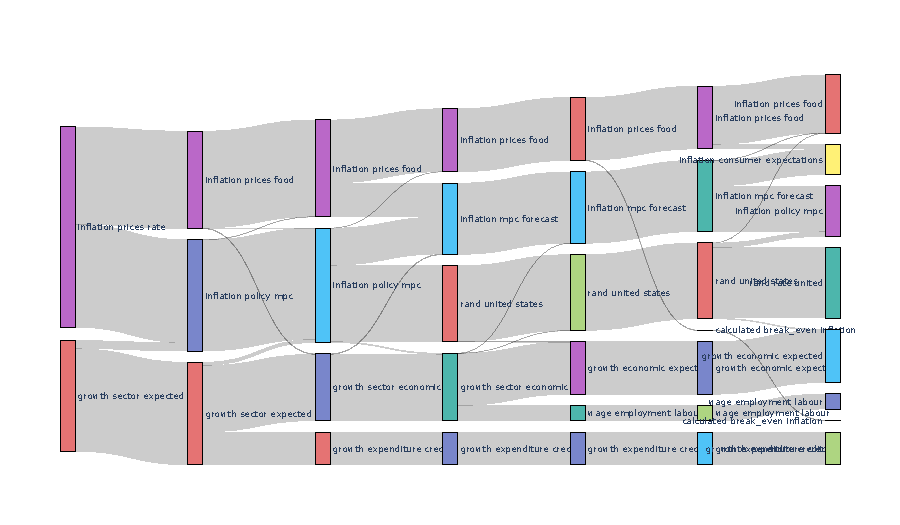
This work shows the relationship between the language used in policy communications and market reactions. Using various NLP techniques, we create holistic metrics that show...
Author Charl van Schoor
TBD
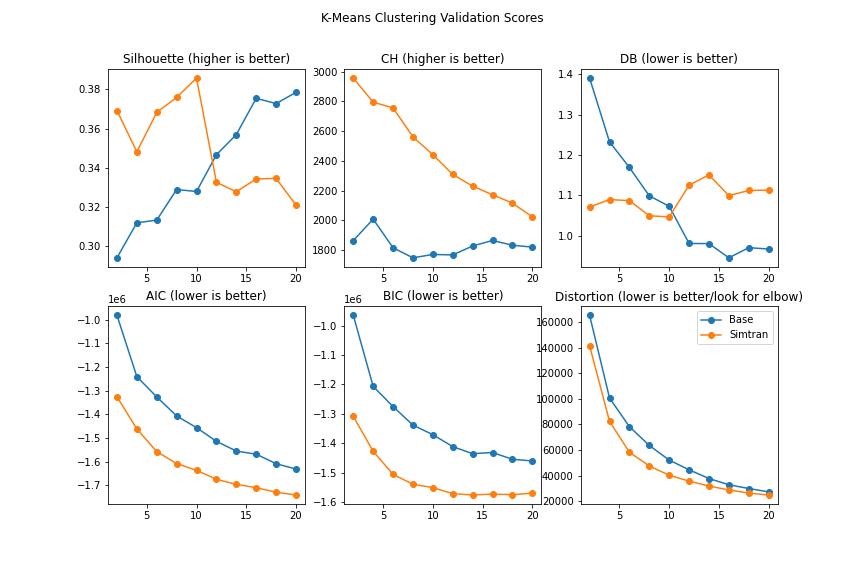
One issue facing various economists using contemporary computational linguistics is the problem of subsetting small text corpora. The issue centers around linear seperability in short and dense corpora, like various economic text. This model aims to solve the problem by transforming sentence embeddings into more similar embeddings, thereby improving seperability with auxiliry clustering. Our results show significant improvements in cluster validation metrics.

